5分钟阅读
AI智能体能力层级揭秘:9大模型RL环境实测,离人类水平还有多远?
AI智能体能力层级揭秘:9大模型RL环境实测,离人类水平还有多远?
目录
构建RL环境的逻辑 Corecraft, Inc. 测试场景解析 智能体能力层级框架 第一步:基础工具使用、规划与目标构建 适应性——当计划遭遇现实变量 接地性——与现实保持连接 常识推理——最后的能力 frontier 那么,GPT-5已接近“人类水平”?
2025年被称为“智能体元年”,AI智能体正从聊天框走出,迈入现实世界。但我们是否真的接近拥有通用智能体?还是仍需十年探索?这个价值万亿的问题核心是:这些智能体究竟能完成多少具备经济价值的实际工作?
为解答这一问题,模型的训练与评估已从单一响应评分,转向对“工具使用+多步骤任务”的综合能力考核。对于测试与训练从业者而言,2025年是RL环境的元年——这类虚拟世界能让模型通过真实多步骤任务自主行动、实验与学习。
我们“招募”了9个AI模型,在自主研发的RL环境中完成150项任务,测试结果如下:
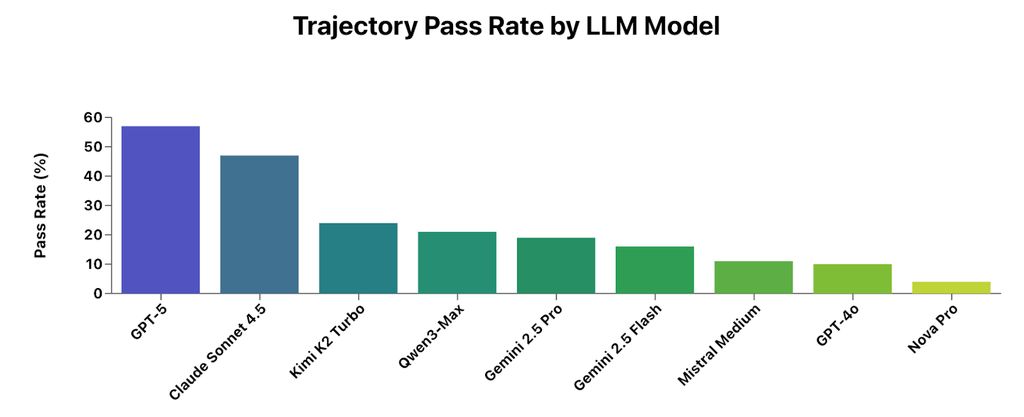
即便是GPT-5与Claude Sonnet 4.5,在该RL环境中仍有超过40%的智能体任务失败。
两个关键结论清晰显现:
- GPT-5与Claude Sonnet 4.5处于第一梯队,领先其他模型;
- 但即便是这两款顶尖模型,任务失败率仍超40%。
原始分数能告诉我们“谁更优”,却无法解释“为何失败”与“如何进阶”。要理解这些结果对现实世界智能体的启示,我们需要先看清:一个真实的RL环境是如何被构建(更准确地说是“演化”)的。
构建RL环境的逻辑
任何RL环境都离不开三大核心要素:
- 连贯的世界模型:定义场景的整体结构框架;
- 一组实体对象:环境中的各类事物及其相互关系;
- 工具系统:智能体与实体对象交互的接口。
要训练出能胜任“虚拟同事”角色的模型,这些环境必须基于真实工作场景,而非抽象模拟。现实世界的复杂系统并非自上而下设计而成,而是随时间逐步演化。
RL环境的一大优势的是,它天然契合这种“演化逻辑”。一旦搭建好基础框架,不同领域的专家就能共同参与,让环境自然生长。
我们的RL环境正是如此构建:在确保“关系与属性连贯性”的框架下,具备领域经验的从业者基于自身工作经历,为环境填充真实的实体对象与任务。
换句话说,智能体的训练环境,正是由它未来将要协作的人类群体共同塑造的。
Corecraft, Inc. 测试场景解析
我们的其中一个RL环境是Corecraft, Inc.——一家高性能电脑配件与定制装机的在线零售商。该环境的“世界模型”就是公司本身,实体对象包括客户、订单、支持工单,以及维持运营的所有记录。
本次测试中,智能体的角色是“客户支持专员”,需处理的任务覆盖:快速产品查询、政策咨询,到需推理多系统交互逻辑的复杂运营流程。
一个简单任务示例: 2025年7月共有多少笔退款?
复杂任务示例: 一位客户订购了一套游戏装机,但最终审核时出现兼容性警告。客户选择了ZentriCore Storm 6600X CPU、SkyForge B550M Micro主板,以及32GB HyperVolt DDR5-5600内存。系统提示三者不兼容,请找出问题所在,并提供最经济的解决方案。
为何选择“客户支持专员”这一角色?因为尽管AI领域最受关注的是前沿研发,但AI的经济价值更多来自对日常工作的赋能。此外,该角色涵盖不同难度、不同类型的任务,是检验“通用智能体基础能力”的理想测试床——无论未来智能体应用于何种场景,这些基础能力都是必备的。
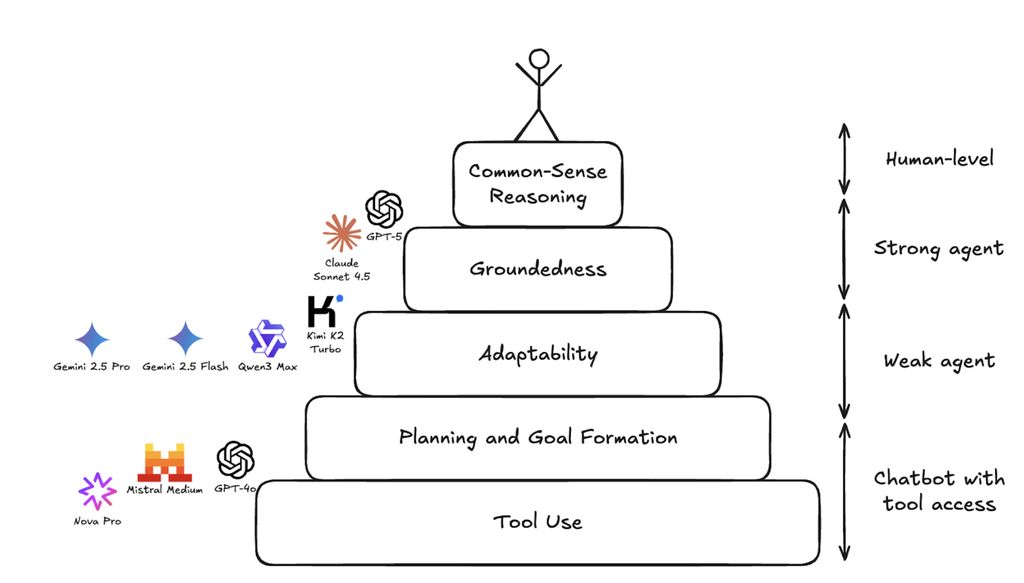
智能体能力层级框架
通过分析模型在该角色中的任务执行轨迹,我们发现:模型的失败模式并非随机,而是集中在特定能力层级。这揭示了一个自然的能力层级——智能体要在开放式环境中连贯运作,需按顺序掌握这些技能。
我们将这一框架命名为智能体能力层级(下图标注了当前主流模型在该金字塔中的位置)。
智能体能力层级从底层到顶层依次为:工具使用、规划能力、适应性、接地性、常识推理,图中同步标注了各AI模型的当前位置。
层级最底部是基础能力:工具使用、目标构建与基础规划。往上是高阶能力:适应性与接地性——这些技能能让模型在应对现实世界的不确定性时,保持上下文连贯性。只有当这些基础能力达到较高熟练度后,模型才能展现出常识推理能力——对未见过的场景进行合理推理,这也是通用智能的核心组成部分。
当然,这一层级只是初步总结。实际中,模型的能力发展并非线性:这些能力相互重叠、彼此强化,且同步演化。达到高熟练度不代表完美——就像顶尖高尔夫球手也可能错过简单推杆,GPT-5与Claude Sonnet 4.5偶尔也会在基础工具使用上出错。关键在于,它们的基础能力已足够稳定,让研发重心能转向高阶技能。
从这个角度看,拆分这些能力层级,并非为了设定刚性顺序,而是为了精准判断:哪些能力已扎实,哪些仍需夯实基础。
第一步:基础工具使用、规划与目标构建
该层级最基础的要求是:模型能否可靠地使用工具达成特定目标;进阶要求是:能否将复杂任务拆解为有意义的子目标,并制定多步骤执行计划。
无法做到这两点的模型,不能称之为“智能体”——它们只是“可调用工具的聊天机器人”。
测试发现,GPT-4o、Mistral Medium与Nova Pro主要处于这一能力阶段。
要完成最基础的智能体任务,模型需稳定实现以下四点:
- 将多步骤任务拆解为子目标;
- 为每个子目标匹配合适的工具,并确定使用顺序;
- 将现有信息映射为工具所需的正确参数;
- 按计划逐步执行,不偏离方向、不遗漏关键步骤。
我们发现,能力较弱的模型无法稳定达成这四点,即便是简单的智能体任务,成功率也如同“掷骰子”。
案例1:三款模型均出现基础工具使用错误 这些错误包括:无法将提示信息合理映射为工具参数,或未遵守MCP schema规范。
测试任务: 找出忠诚度等级为黄金(gold)或铂金(platinum)、且有未处理高优先级支持工单的客户。
Nova Pro的错误尝试: “gold”显然不是客户ID!(误将忠诚度等级作为客户ID参数传入)
GPT-4o正确第一步:先搜索黄金与铂金等级的客户,但在搜索高优先级工单时出现工具使用错误——它试图将“high”传入“status”参数,却忽略了工具中专门的“priority”参数。
Mistral Medium的错误:在搜索客户时,向“customer_id”参数传入了数组——而MCP schema明确规定该参数仅接受字符串类型。
案例2:三款模型均在规划与执行上遇阻
测试任务: SkyForge X670E Pro主板已发布产品召回通知,请提供2025年8月订购该产品、且订单状态为“已完成(fulfilled)”“已付款(paid)”或“待处理(pending)”的客户姓名列表(以项目符号呈现)。
正确执行流程:
- 使用
searchProducts工具查询该产品的ID(该工具支持通过文本搜索产品记录,并返回完整产品信息); - 使用
searchOrders工具查找包含该产品ID的相关订单(需筛选状态为fulfilled/paid/pending的订单); - 输出所有相关客户姓名。
Nova Pro与Mistral Medium在第一步就失败:直接跳过产品ID查询,将产品名称直接传入 searchOrders 工具的“product_id”参数——这是对“提示信息”与“工具参数要求”的推理失误。它们似乎只选择了“看似能直接出结果”的工具,而非结合所有可用工具制定完整计划。
GPT-4o表现稍好:正确查询到产品ID,也执行了订单搜索,但仅筛选了“fulfilled”状态的订单,完全遗漏了“paid”与“pending”——这是典型的规划疏漏,缺失了关键子目标。
这些案例只是冰山一角。工具使用错误与规划失败的形式多种多样,但这类基础失误是“未经过智能体专项训练”模型的共性问题。在模型能稳定掌握“工具推理”与“任务拆解”前,讨论其在智能体场景下的通用推理能力,无异于徒劳。
而当模型掌握了规划与工具使用能力后,就需要迈向下一步。
适应性——当计划遭遇现实变量
恭喜,模型已经能制定计划了。但现实世界往往不会完全配合。这就需要“适应性”:当现实反馈超出预期时,能及时更新计划。
即便模型能正确理解工具,执行过程中仍可能出现问题:工具文档不完整、信息存在歧义,或制定完整计划前需要补充更多信息。能否应对意外结果、在任务中途调整计划,是模型需要掌握的下一项关键技能。
当前的Gemini 2.5与Qwen3模型常在此处遇阻:它们能执行合理的工具调用序列,但当某一步骤出错时,往往无法做出有效反应。
测试任务示例: 你好,我是Penny Whitcomb。我想升级显卡,一直使用Vortex Labs的产品。能否帮我查询RX820L和RX780这两款显卡,是否与我上一次订单中的配件兼容?并告知每款的价格。
正确执行流程:
- 使用
searchCustomers工具查询Penny的忠诚度等级(用于确定定价)与客户ID(用于查询历史订单); - 使用
searchOrders工具查找Penny上一次订单中的产品; - 使用
searchProducts工具查询Vortex Labs这两款显卡的产品ID; - 使用
validateBuildCompatibility工具验证新显卡与历史订单配件的兼容性。
Gemini 2.5 Flash、Gemini 2.5 Pro与Qwen3 Max均能制定正确的工具调用序列,但在第三步遭遇相同问题:搜索两款显卡时未返回任何结果。
原因很简单:它们将“Vortex Labs”(带空格)作为“brand”参数传入,而系统中该品牌的存储格式是“VortexLabs”(无空格)。
模型无法提前知晓这一格式差异,问题的关键在于后续反应:这三款模型均直接将“无结果”视为最终答案,回复“Corecraft不销售该显卡”,而未尝试调整搜索策略。
相比之下,Claude Sonnet 4.5在遇到相同问题时,展现了主动适应性:
它会尝试不同的搜索参数组合,这正是人类面对类似问题时的自然反应。
能力较弱的模型虽有正确计划,却过于僵化,无法应对执行中的变量。而现实世界的任务很少能一次顺利完成,“灵活调整”是必备技能。
接地性——与现实保持连接
“接地性”是另一类常见失败点——指模型保持“上下文连贯性”的能力:不虚构ID、不偏离任务主题、不编造与现实脱节的事实。
Kimi K2 Turbo的规划与适应性优于Qwen3 Max和Gemini系列,但在“保持上下文接地”方面存在明显问题。
示例1:年份信息混淆 系统提示的第一行明确标注了当前年份,但Kimi在工具调用中频繁出错:当被要求查询2025年8月25-31日的订单时,它搜索的是2024年的记录;而在最终回复中,又切换回2025年。
Claude Sonnet 4.5整体表现出色,但也存在接地性问题——这也是它与GPT-5拉开差距的重要因素。
示例2:上下文脱节与自我修正 Claude需查找“9月30日前下单但尚未发货”的客户详情。在正确找到其中一笔相关订单后,它尝试用一个明显虚构的邮箱地址搜索客户信息——这是典型的接地性缺失。
但值得肯定的是,当搜索失败后,Claude展现了强大的适应性,及时修正了错误。
尽管Claude的“自我修正”能力令人印象深刻,但对于需要独立运作的智能体而言,“上下文锚定能力不足”仍是关键隐患。
示例3:隐蔽的接地性错误 Claude被要求查询支持工单并标注优先级。它正确调用工具查找“普通优先级(normal)”的工单,返回结果中包含以下两笔:
这两笔工单的优先级均明确标注为“normal”,但Claude的最终回复却出现错误:将它们归为“高优先级(high)”,同时又在“普通优先级”部分重复列出,并注明“已列为高优先级”——不仅与上下文脱节,甚至存在内部逻辑矛盾。
这类隐蔽的接地性错误更难被察觉,有时会直接融入最终答案而未被发现。
常识推理——最后的能力 frontier
当模型能可靠使用工具、有效规划、灵活调整计划,且保持上下文接地后,要达到“人类水平”,还需突破最后一道屏障:常识推理。
这已进入更模糊的“通用人工智能(AGI)”领域。常识推理没有明确的定义,但对于通用智能体而言至关重要——它是“通用智能”中的“通用”所在,是无法通过显性训练获得的能力:面对陌生场景时的表现。此时,模型已能稳定展现智能体行为,但核心问题变成:它的“智能程度”如何?
本次测试中,常识推理能力的差距,是GPT-5与人类水平的主要区别。
示例1:关键信息推理缺失 测试任务: 识别当前分类为“其他(other)”的支持工单中,哪些应重新归类为“退货(returns)”。
GPT-5正确调用工具找到相关工单,其中包含以下这条:
该工单本应被重新归类,但需要一点常识推理:
- 客户明确要求退款,可能属于“退货”或“取消订单”;
- 但“包裹几小时前已送达”这一细节是关键:客户已收到商品;
- 结合这一信息,该工单应明确归类为“退货”。
GPT-5收集了所有正确信息,却未能建立关键关联,最终未将该工单纳入重新分类列表。
示例2:缺乏高效推理策略 另一项任务要求识别“可能是游戏玩家”的客户,提示中建议“查找购买显卡、含显卡的整机,或产品描述提及‘游戏’的客户”。
合理的执行策略是:通过工具筛选“显卡类产品”“游戏相关描述的产品”,再查找2025年8月包含这些产品的订单——现有工具完全支持这一流程。
但GPT-5采用了低效策略:为避免超出搜索结果上限,它逐天查询8月所有订单(共31天),再通过 getProduct 工具查询订单中具体产品的详情,仅通过产品ID中是否包含“graph”或“gaming”来判断是否与游戏相关。Claude也采用了完全相同的低效策略。
GPT-5的行为连贯且执行了计划,但并非“合理”的计划——缺乏常识推理带来的高效策略判断。
示例3:任务意图误解 测试任务: 我玩游戏时一直掉帧,想升级显卡。预算900美元以下,能买到的最高端显卡是什么?请提供价格和所有参数。我的账户注册姓名应为Sarah Kim。
GPT-5正确获取了产品信息,但未查询Sarah Kim的客户记录(以确定忠诚度等级和个性化定价),反而回复了通用政策信息。
根本原因是常识推理缺失:它误解了任务意图,将“我的账户注册姓名应为Sarah Kim”解读为“修改账户姓名”的指令,而非“查询者身份为Sarah Kim”的线索。
单看这句话确实存在歧义,但结合上下文,通过常识推理本可明确意图:
- 客户未提供其他身份信息,无法通过其他方式查询账户;
- 使用
searchCustomers工具可找到名为“Sarah Kim”的现有客户; - “修改账户姓名”与“查询显卡价格”完全无关,而查询忠诚度等级能为客户提供精准定价——这才是与任务相关的合理操作。
这些本可通过常识推理明确的逻辑,GPT-5未能实现。这并非策略或执行错误,而是在环境与任务上下文中的“合理推理能力”缺失。
那么,GPT-5已接近“人类水平”?
或许开篇的测试结果图并非100%准确。真实情况更可能是这样:
换句话说,即便模型在工具使用、规划、适应性、接地性这四大基础能力上达到高熟练度,也不代表它已成为“能在现实世界胜任工作的人类水平智能体”。这四大能力只是“前提”——只有掌握它们,我们才能开始讨论模型在真实环境中的常识推理表现。
常识推理目前仍无法被清晰定义,但“缺失时很容易察觉”。它究竟是一组可识别、可训练的子技能,还是大规模现实世界训练后的涌现能力,仍有待验证。而这一问题的答案,将决定AI发展的下一阶段方向。
2025年成为“智能体元年”,并非因为我们已实现强大的通用智能体,而是因为我们终于拥有了“能稳定展现连贯行为”的智能体——足以让我们开始分析和探讨它们的常识推理能力。未来的挑战,是训练和研究那些正快速逼近人类智能水平的AI。至于要多久才能弥合这最后的差距,仍是一个开放问题。
更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。